使用流程
1、下载模型
登录魔搭社区https://modelscope.cn/models查找模型
可以阅读下官方文档,写的很详细
下载模型
cd /mnt/vllm-models
mkdir gemma-3-27b-it //创建一个目录用来存放模型权重,名字自定义
modelscope download --model 'LLM-Research/gemma-3-27b-it' --local_dir '/mnt/vllm-models/gemma-3-27b-it' //从魔搭社区下载模型权重到本地指定路径下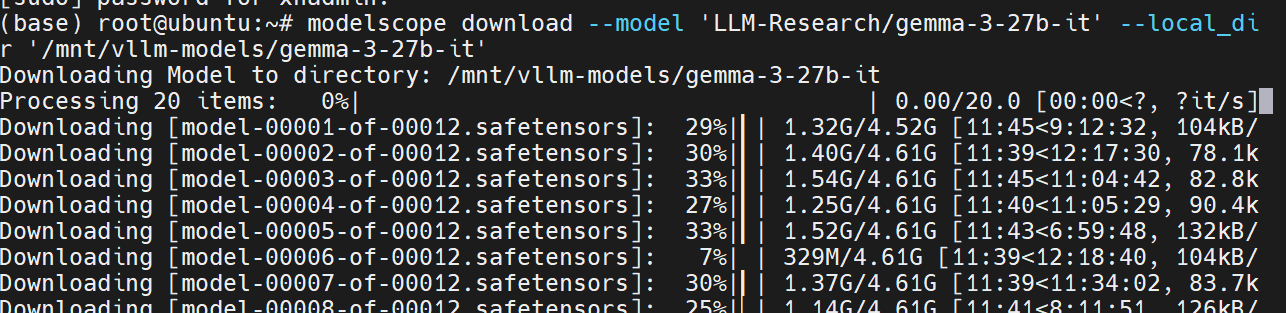
2、启动模型
vllm serve /mnt/vllm-models/QwQ-32B \
--served-model-name QwQ-32B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 2 \
--max-model-len 8192参数解释:
/mnt/vllm-models/QwQ-32B 是存放模型的路径
--served-model-name QwQ-32B 为模型指定一个名字,名字随便取,只是用来方便后面Dify进行调用的
--host 0.0.0.0 允许外部地址访问,0.0.0.0是允许所有
--port 8000 访问的接口
--tensor-parallel-size 2 调用的GPU数量,我们公司2两个,所以是2,有4个就写4
--max-model-len 8192 上下文长度限制,这也取决于硬件性能。
看到如下日志,说明模型已经成功运行起来了

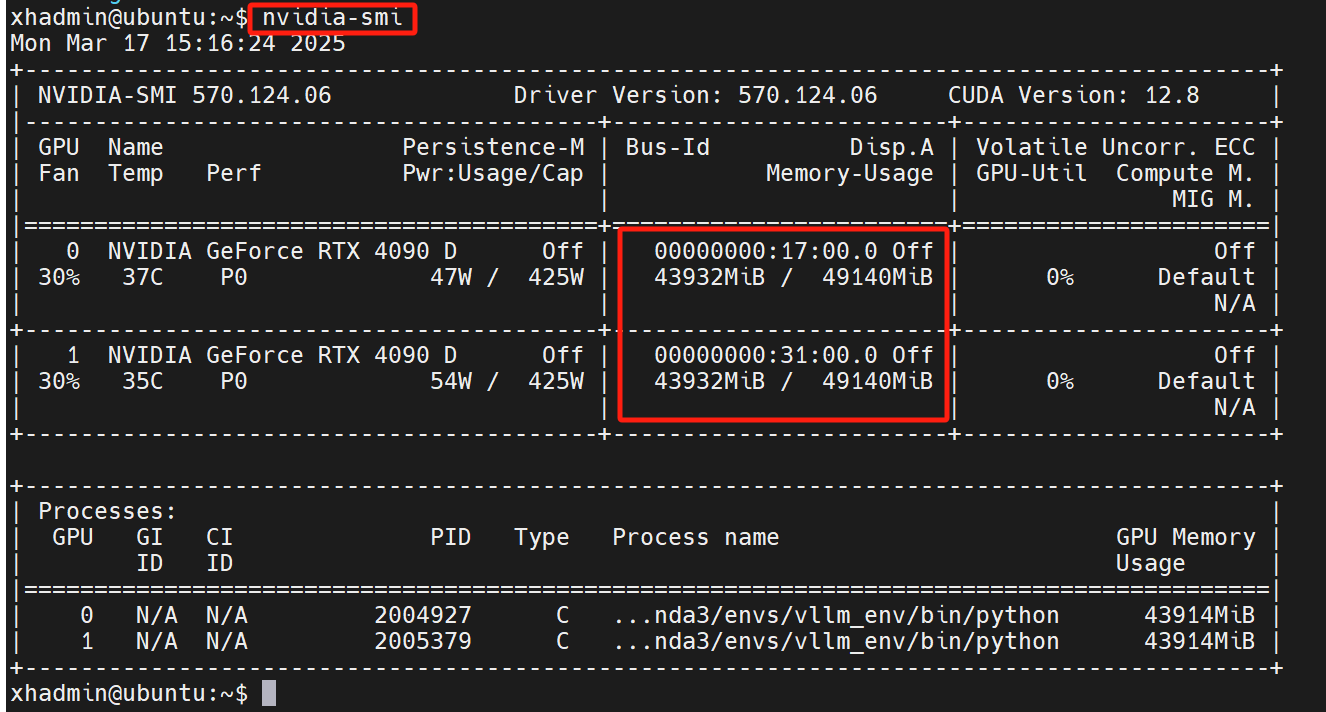
可以新开一个窗口执行nvidia-smi查看GPU使用率
3、Dify对接模型
登录DIfy http://ai.xuanheng.info
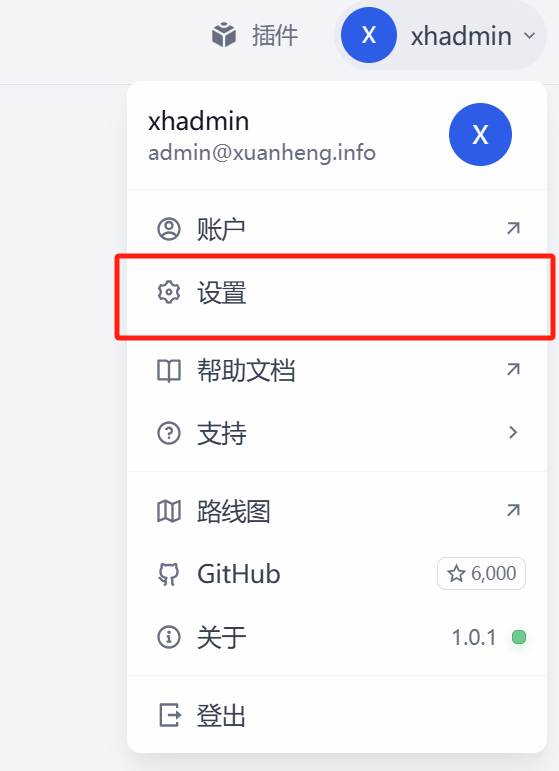
进入设置
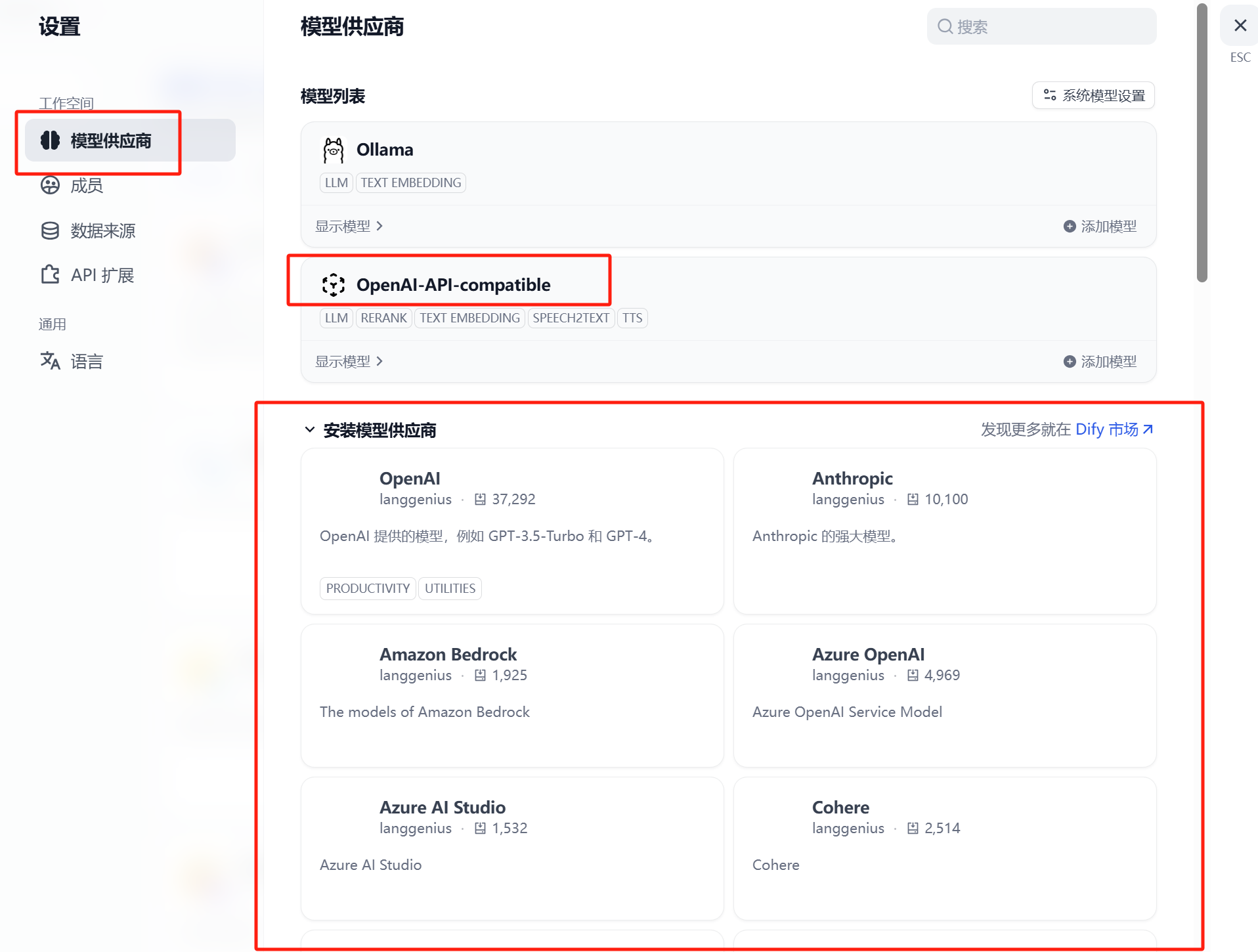
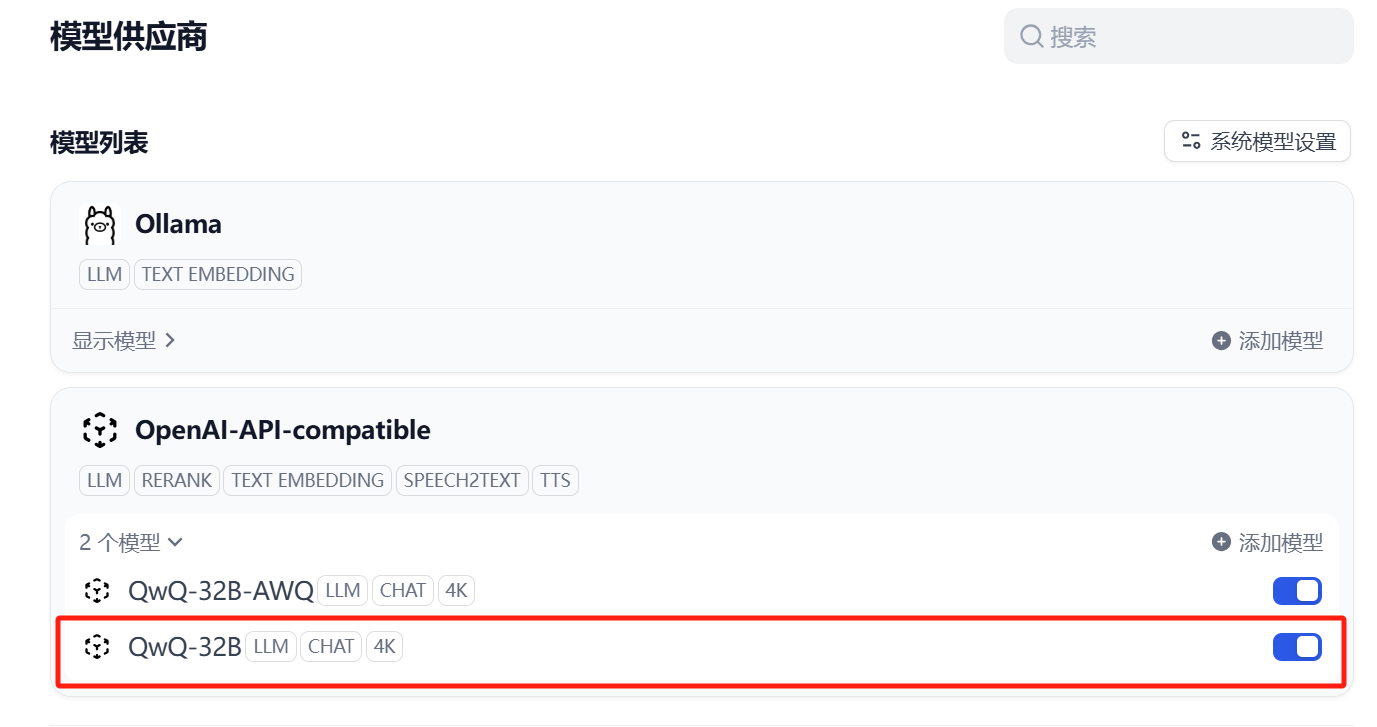
模型供应商:找到并安装OpenAI-API-compatible
(因为vllm没有自己的api接口,所以使用openai-api来对接)
模型名称:填写运行时候模型的name参数
API Key:随便输
API endpoint URL:http://10.0.0.201:8000/v1
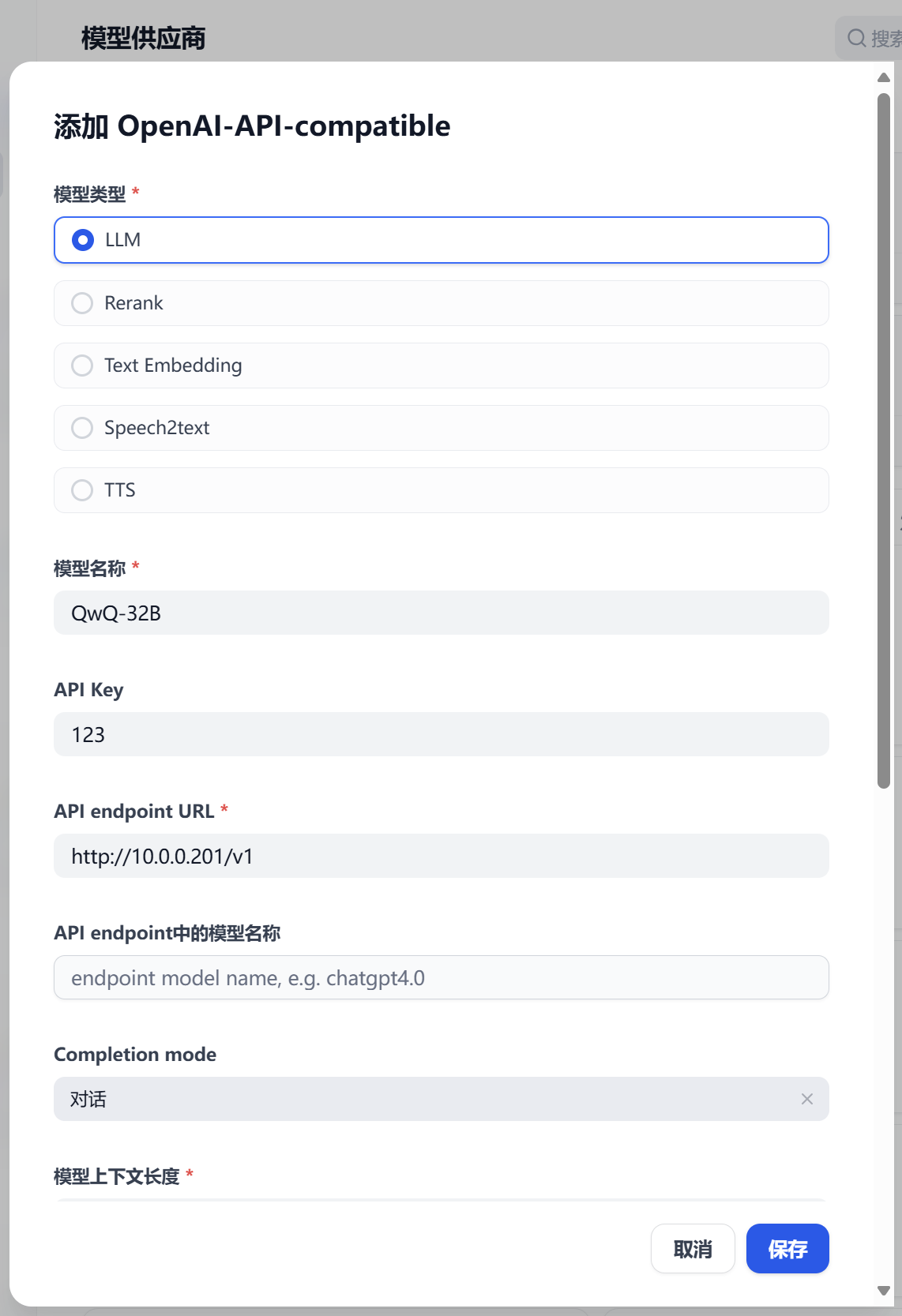
添加成功
4、Dify导入添加知识库
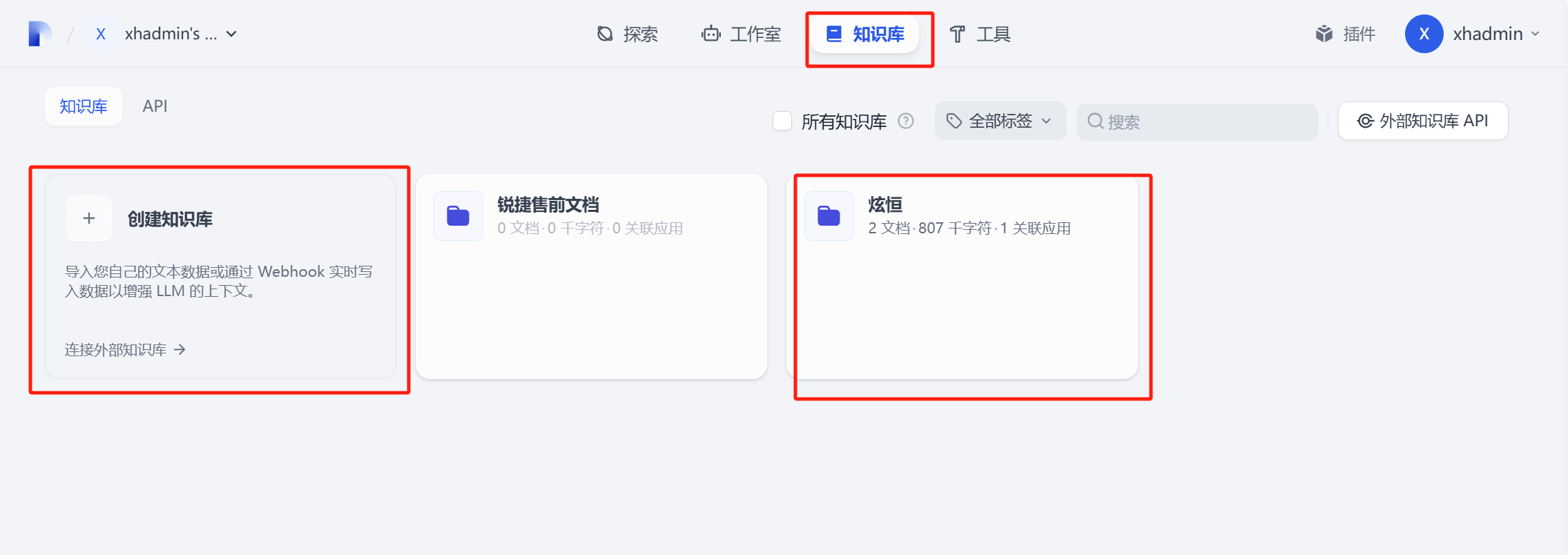
点击知识库,创建知识库
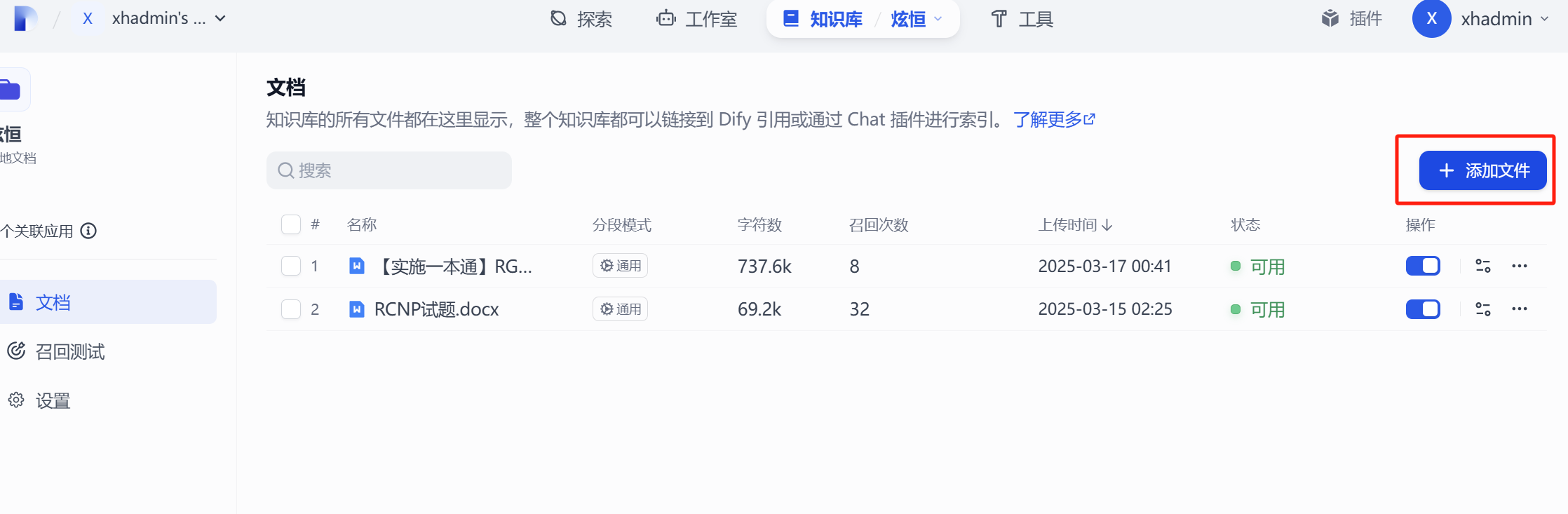
添加文件
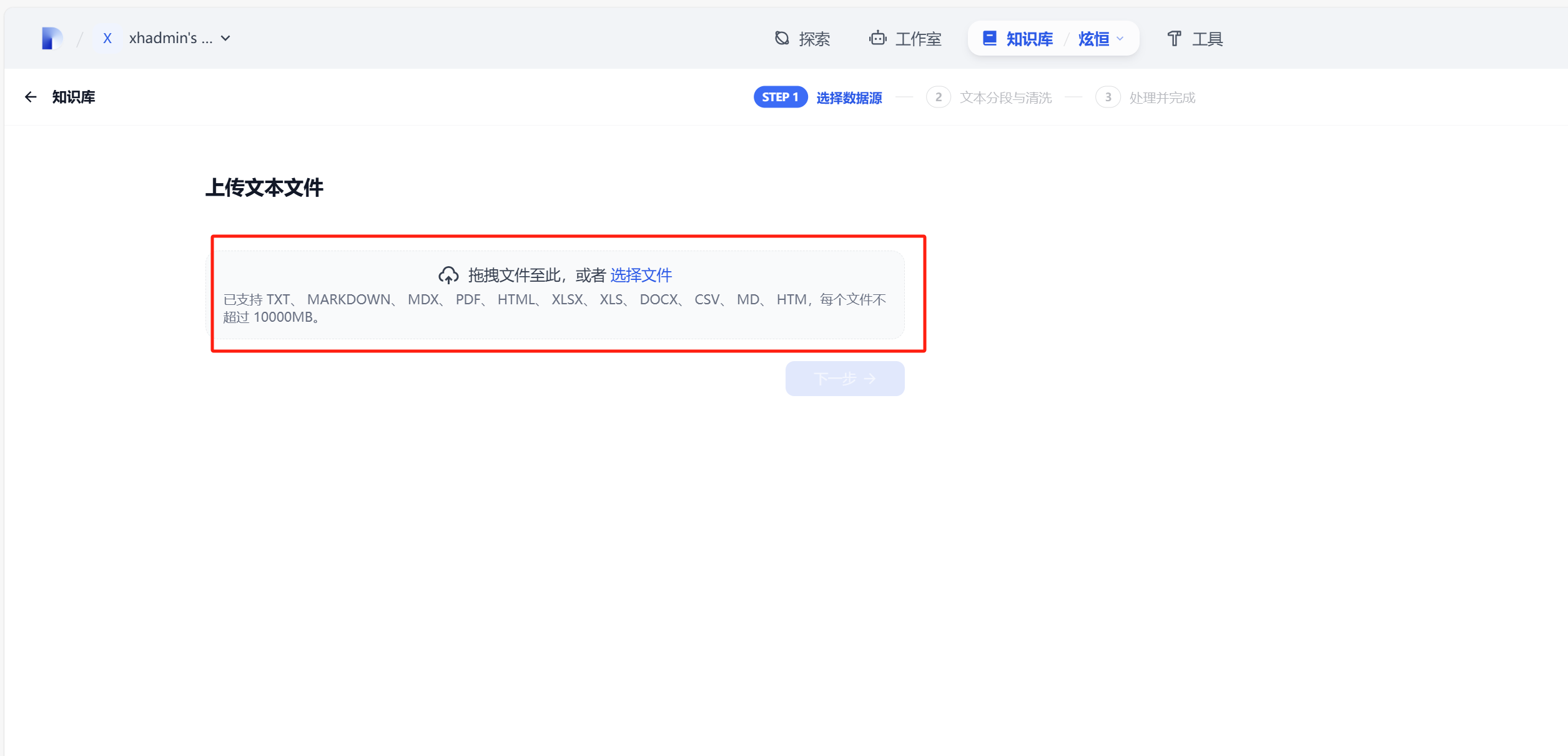
上传文件
5、Dify创建工作流